
去年参加了Datacon DNS恶意流量方向的比赛,拿了第五,差点拿到奖orz,今年参加了部分赛题的内部评估,以下是做题记录。
DNS 恶意域名分析题目一-种子寻找记之DGA算法分析
赛题信息
设计说明
DGA(Domain generation algorithm,域名生成算法)是一种利用特定种子字符,结合加密算法,进而生成一系列伪随机恶意域名的方法。恶意软件可使用DGA逃避域名黑名单的检测。
本题中,选手需从给定的DGA样本中通过逆向分析发现其中存在的DGA算法。通过对DGA算法的分析,根据给出的同算法但不同种子生产的域名获得新的种子,最终给出使用新种子生产的所有域名。
数据说明
- sample1.exe、sample2.exe、sample3.exe,不同DGA算法的三个样本
- 20200510_domains1.txt、20200510_domains2.txt、20200510_domains3.txt,各样本对应的同算法但不同种子的样本生产的域名,若算法时间相关,则生产时间为2020年5月10日
提交形式
选手提交3个txt文件,提交文件的命名规则和内容如下:
domains1.txt
使用sample1.exe中算法和新种子生产的算法规定个数的域名。每个域名一行。
domains2.txt
使用sample2.exe中算法和新种子生产的算法规定个数的域名。每个域名一行。
domains3.txt
使用sample3.exe中算法和新种子生产的算法规定个数的域名。每个域名一行。
解题过程
这个题主要是考察基本逆向+算法分析,之前也没做过逆向,这次正好算是入了门,踩了挺多逆向的坑…
sample1
IDA打开,找不到main函数,文本模式下搜main,找到入口函数:
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
看起来,2020、4、6是日期,最后一个参数是种子,反编译dga_v2函数:
1 | int __cdecl dga_v2(int a1, char a2, char a3, unsigned int a4) |
改了下v22的类型,分析算法流程,大概就是长度为8的数组,前三个是年月日,第四个是0,后面四个是v14(次数)的低32bit,一个占8bit,然后与种子异或,md5得到结果再按程序一个逻辑得到可见字符,然后根据v14确定后缀。
这里MD5Update这些函数信息理应是隐藏的,出题人没注意,正式比赛应该给修正了,其实通过 Magic number 可以判断是 md5,我还下了断点动态调试验证了一下。
其实只有种子未知,直接照着逻辑实现一遍,拿第一个域名爆破种子就好了。md5算法是网上找的一个实现:https://blog.csdn.net/weixin_42167759/article/details/81209320。
1 |
|
跑了挺久的,得到种子是1836927723,直接生成就好了。
sample2
拖到IDA反汇编,看到就一个dga函数:
1 | dga("cw3OGGsoaako7GSGG3", "umyyobuorstfabj.com", (char (*)[5])v4, 3, 1000); |
v4可以看到是域名的后缀名,包括[‘pw’, ‘us’, ‘club’]。
看dga函数:
1 | int __cdecl dga(char *a1, char *a2, char (*a3)[5], int a4, int a5) |
生成域名的重点代码是这段:
1 | do |
下面是加后缀的,不用管。
里面涉及的变量,v18是v17赋值,v17是“cw3OGGsoaako7GSGG3”的ascii码的和(低8位)。
v11是一个不知道哪的数,v25是“umyyobuorstfabj.com”,v24未知。v24很奇怪,用法是类似数组的用法,声明却是int,手动改成int类型的数组,重新反编译。
1 | int __cdecl dga(char *a1, char *a2, char (*a3)[5], int a4, int a5) |
这样就好看多了,之前的v24和v25指向的数据是同一数据。
往下看,发现v5 = v21;,v21会作为下一个域名生成算法的输入,覆盖”umyyobuorstfabj.com”。
现在也不知道选了哪个后缀的域名作为的v21,动态调一下,发现是club。
我们没有a1和a2,但是只有第一个域名生成用到了a2,后面的域名生成基于上一个域名,我们选一组挨着的域名,a2的问题解决了。a1也只是用了个ascii码的和,256种可能。
这里面还有个v10不知道,256种可能,所以我们可以爆破256*256种可能,还原出这两个值。
得到了两组值:84, 119与85, 48。
然后直接照着算法逻辑跑可以得到后面的所有域名,与txt中结果比对,发现84,119的是正确的。
脚本:
1 | s1 = "xuvsxyrbjiyv" |
(unsigned int)(unsigned __int8)v16 - 98 <= 0x17 这个判断,注意无符号数,开始python没注意到这个问题,动态调试了一会才发现这里的问题。
sample3
拖进IDA分析,代码很简单,指定随机数种子取余来生成字符串。32bit的种子,但是给的100个域名是随机采样的100个域名,打乱了顺序,没法直接爆破。
应该是要看rand的源码,参考https://crypto.stackexchange.com/questions/6760/how-does-the-rand-function-in-c-work
关键源码:
1 | static long holdrand = 1L; |
可以看到其实生成随机数算法很简单,就一行。而且每次生成的随机数仅取决于holdrand,生成一个随机数的同时指定下一次生成随机数的holdrand,就是一个递推公式。
这个题目相当于给了我们100个连续的随机数片段(模35的结果),但是我们不知道每个片段的index。
同时程序在输出dga域名时,输出第一个dga域名只需要生成一个dga;输出第二个dga域名时要生成两个dga,把最后一个输出;输出第三个dga域名时要生成三个dga,把最后的输出,也就是说程序共生成了1+2+3+…+1000,即500500 个域名。
其实定义种子就是定义一个holdrand,我们任意选一个输出域名,直接爆破种子,可以得到生成这个域名前的holdrand。
就拿第一个域名为例,直接爆破:
1 |
|
得到682174533,也就是说生成13mrjyvjjp4azbbkt7之前,holdrand的值是682174533。
接下来我们需要确定,这个域名是第几个输出的。我们可以以682174533为种子一直生成域名,把每个域名与题目中的100个域名对比,相等就记录下来是第几个生成的,代码:
1 |
|
得到:
1 | 1,725,1450,2176,5821,6553,34340,35110,35881,38975,39751,67541,68353,69166,102506, |
这些对应的域名都是在输出13mrjyvjjp4azbbkt7之后输出的,输出的数字就是偏移域名数量。
然后我们把500500个域名中输出域名的index列出来,遍历所有index,如果对于上面的每个偏移,index加上偏移的结果依然在index的list中,那么我们就找到13mrjyvjjp4azbbkt7的index(即13mrjyvjjp4azbbkt7是程序生成的第几个域名)。
Python脚本:
1 | index_list = [] |
输出261726,也就是说这个域名是程序随机生成的第261726个域名。
现在我们需要通过现在的状态,还原初始种子。递推公式是holdrand = holdrand * 214013L + 2531011L,这里long类型会产生溢出,可能出现负数,导致无法直接逆推回去。
查阅c语言存储long类型的相关知识,原理是一个long类型用32bit存储,最高位作为正负标志位,其余31bit记录值,如果计算结果超出32bit,那就只取低32bit。
这里想了很久如何逆推解方程,最后发现其实不用管什么正负,因为生成的随机数是holdrand 32位中的高16位,无论怎么溢出,只要关心holdrand低32位就好了,即使正负标志位是1,我们也可以当成正常的32bit正数来计算。这样可以把问题转成解同余方程:
1 | a*x+b=c mod n |
n是2^32,a是214013L,b是2531011L,解方程直接减b再乘逆元就好了。
这个域名是第261726个生成的域名,我们只需要逆推 (261726-1)*19次状态,就可以还原到最初的seed。
Python脚本:
1 | from gmpy2 import * |
得到初始seed是77980108,然后生成dga域名就好了:
1 |
|
发现给的100个域名都在我们生成的域名里,证明答案无误。
僵尸网络分析题目一-Botnet追踪—追到我就让你嘿嘿嘿
这个题我评估后出题人根据我的反馈,对题目做了一定的调整。
赛题信息
设计说明
Datacon software是一家以IOT产品开发为主要业务的公司,他们在开源Web server GoAhead的基础上定制了一款名为XGoAhead的Web server使用在自己的产品中。某天Datacon software收到外部情报反馈:其定制开发的XGoAhead疑似存在漏洞,且已遭到僵尸网络利用。现在你的任务是找到这个僵尸网络的C2域名。
代码与数据说明
目前已知的线索如下
- XGoAhead最新版本源码
- XGoAhead最新版本源码
- Passive DNS数据
提供的XGoAhead软件代码只能运行在Linux操作系统上且须使用make工具构建,推荐使用Ubuntu 18.04 x86_64或Centos 7 x86_64,不推荐在其他系统/平台上使用。
提供的公网Web蜜罐数据仅为蜜罐服务器接收到的来自公网的流量,远不能覆盖整个互联网的情况,仅为观测样本。
提供的Passive DNS仅为小范围Client IP的数据,远不能覆盖整个互联网的情况,仅为观测样本。
数据格式
- Web蜜罐数据
该数据位于压缩包中的honeypot.json文件,其来源于公网部署的Web蜜罐,数据采集的时间范围是2020年5月。文件中每一行为一个JSON字符串,代表一条蜜罐日志,即针对蜜罐的一次HTTP请求,详细字段解释如下:
| 字段 | 解释 |
|---|---|
| eventid | 事件类型,数据文件中均为“attack.web” |
| method | HTTP method |
| body | HTTP body |
| url | HTTP request URL |
| header | HTTP request headers |
| path | HTTP request path |
| protocol | 应用层协议,数据文件中均为“http” |
| src_ip | 源IP地址(已加盐哈希处理) |
| src_port | 源端口 |
| dst_port | 目的端口 |
| timestamp | 数据捕获的时间(格林尼治时间) |
- Passive DNS 数据
该数据位于access.cvs中,该数据表示DNS请求记录,即DNS客户端IP请求解析的域名记录。该数据采集于2020年5月的某一天。格式为CSV,每行三个字段,分别为“域名”、“客户端IP(已加盐哈希处理)”、“一小时内的请求次数”,请求时间已去除(脱敏)。
提交形式
题目修改前提交内容:
- 可能利用XGoAhead漏洞的僵尸网络的C2域名
答案通过文本文件提交,如果找到了多个C2域名则一行一个C2域名。文件使用ASCII编码,换行符为“\n”,文件末尾留一个空行。
- XGoAhead中漏洞所在的文件名和函数名(如果XGoAhead存在漏洞则需要提交该答案)
通过文本文件提交,格式为“文件名:函数名”(冒号为英文冒号,大小写敏感),如存在多个漏洞则一行一个漏洞,换行符为“\n”,文件末尾留一个空行。
题目修改后提交内容:
- 提交可能感染僵尸网络的IP
解题过程
先讲下当时做题的过程。
题目要求找到这个僵尸网络的C2域名,并找出 xgoahead 漏洞点。
做题思路应该大致是这样
- 源码审计,找出漏洞点
- 根据漏洞,从蜜罐流量中找出攻击流量
- 根据攻击流量的源IP,在 passive dns 中找出 C2 域名。
源码审计
既然是基于 goahead 改的,先把 goahead 源码拉下来 diff 一下。goahead 网上的源码下载链接大多挂了,github也没了,在这里下到了 4.1.3 的源码:https://www.embedthis.com/goahead/download.html
拉下来 diff 一下。
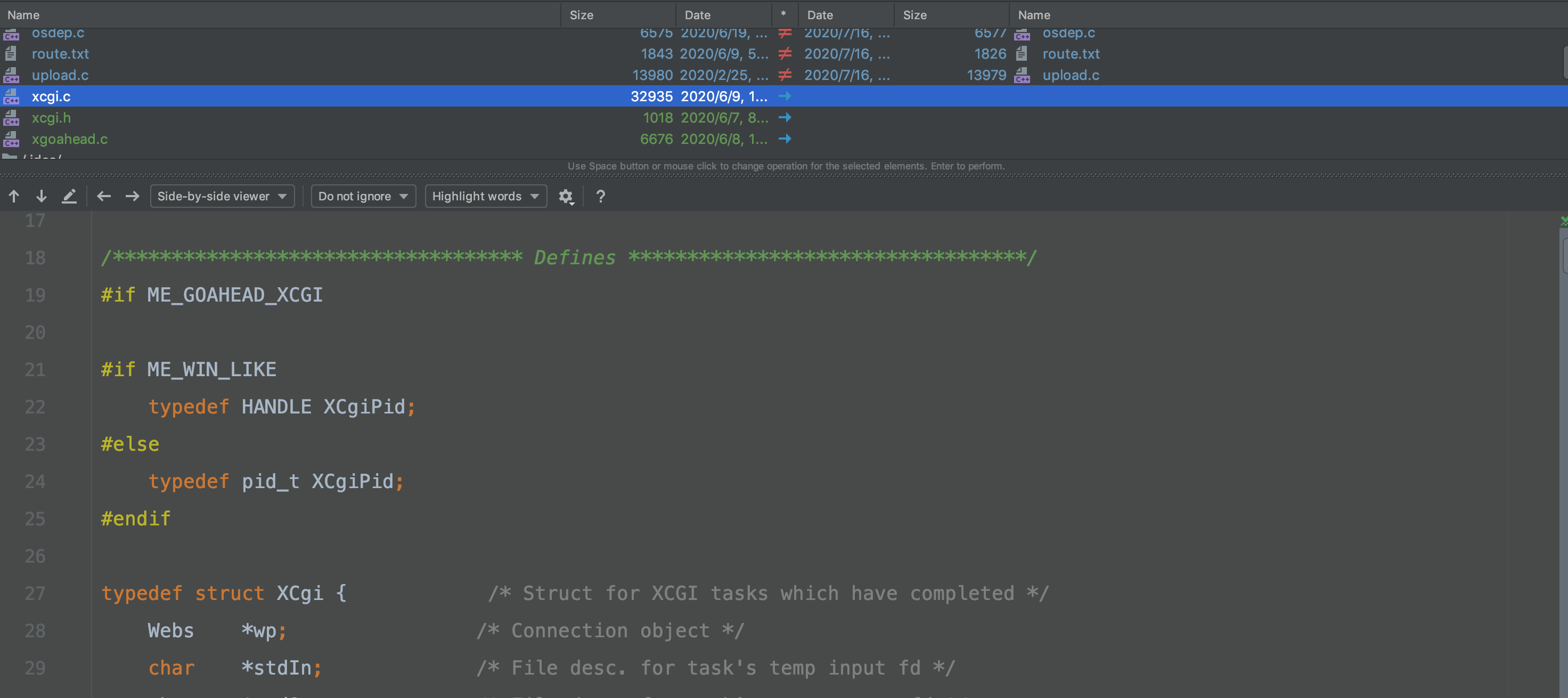
主要的改动就是增加了一个 xcgi,这个 xcgi 看起来跟 cgi 功能差不多。其他没啥自己写的功能代码,搜一波 goahead 的漏洞:
CVE-2019-5096 有个RCE,参考 https://www.anquanke.com/post/id/194322,不过 xgoahead 已经修复了。
CVE-2017-17562 有个 cgi 的 RCE,参考 https://xz.aliyun.com/t/6407#toc-2, xgoahead 也修复了,是官方的解决方案:
1 | envp = walloc(envpsize * sizeof(char*)); |
增加了过滤。
但是 xcgi 没有这么严格的过滤,只过滤了 LD_:
1 | /* |
这里应该是漏洞点。(并不知道如何 bypass)
跟那个漏洞,还发现一处奇怪的地方:
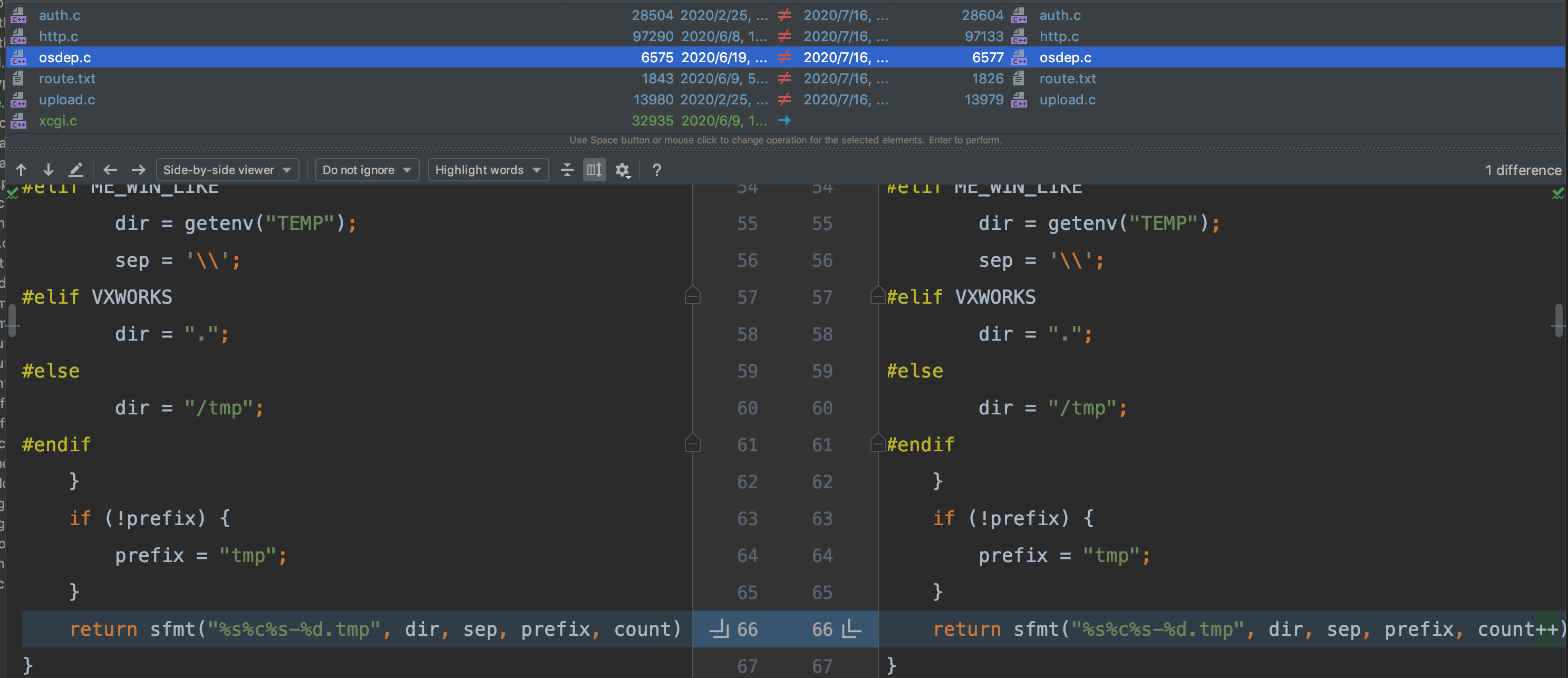
Xgoahead 对临时文件的文件名处理,把 count++ 取消了,那一直都是只能写那一个文件。
数据分析
数据量较大,做分析处理比较麻烦,考虑导入数据库,方便后续操作。试了很多种方法,最后还是用 Python 解析数据再入库。
倒入数据库脚本:
1 | # -*- coding: UTF-8 -*- |
处理数据时,Access.csv 部分数据有些问题,如6416行,217333行,直接跳过处理了,还不少,大部分是多了请求的ip。

绝大部分请求ip都是 cfda2160b0298e40a2d3fbe79e8d309a,感觉对做题没啥影响,因为蜜罐数据里根本就没有这个ip。
导入库后,大体观察一下,寻找漏洞特征。
如果利用 xcgi 那个漏洞,按照 xgoahead 源码的路由,要访问 /xcgi,不过没发现这样的流量。需要上传恶意 so 文件,流量里也有传 elf 的。
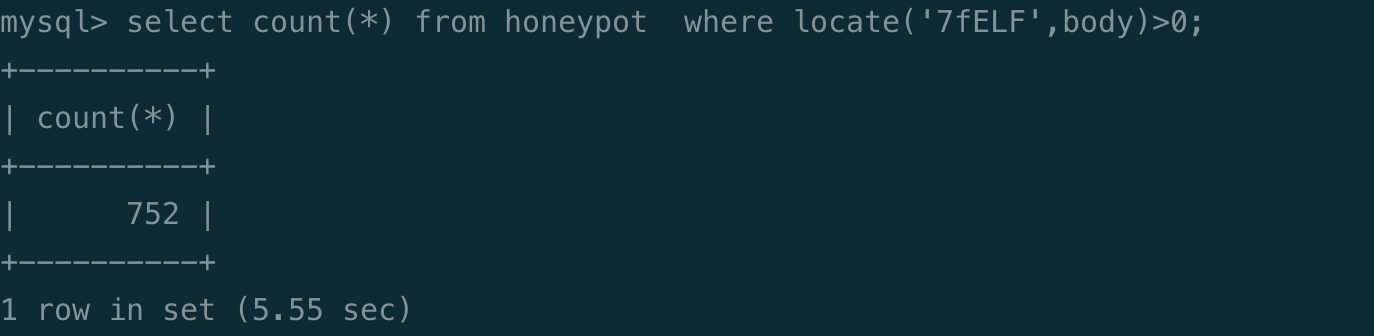
(不过发现有的 elf 拖下来逆向分析,没啥恶意行为)
看一下有多少 ip 发出了上传 so 的请求:
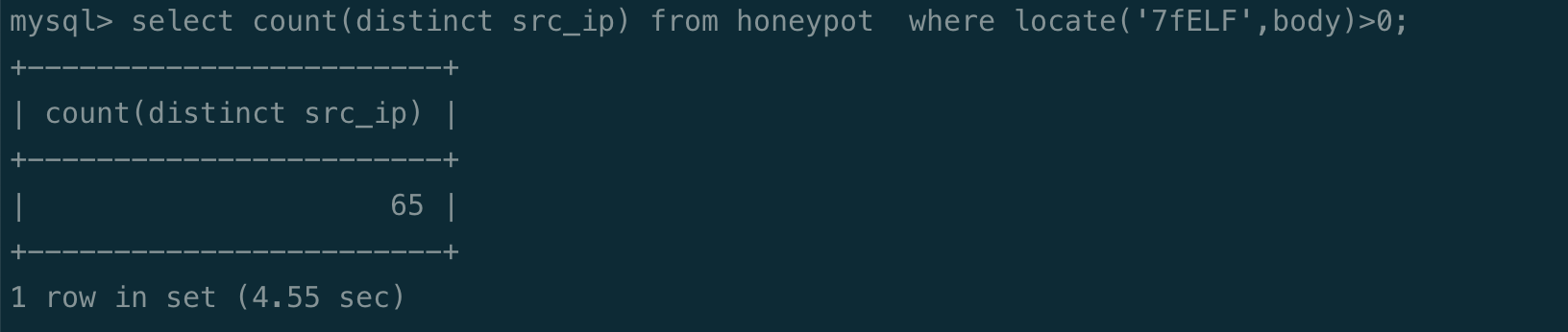
发现是 65 个,可以把这些 ip 拿出来,去 access.csv 看一下这些 ip 的 dns请求。
1 | # -*- coding: UTF-8 -*- |
发现 passivedns 中只有其中两个 ip 的记录 : 625210b633ed23166798790a3180b6dc 与 eef5239efd6c7cc9f2e08f4a6f45d76b。看了下蜜罐流量,两个 ip 都是只有一条记录,上传的 elf 拖下来看了下也是恶意的:

而且文件名有 tmp/tmp-0.tmp,和之前修改的那部分代码可以对应上。
看起来这两个 ip 还请求了不少正常的域名,C2 域名应该是公共的吧,把这两个 ip 请求的域名取下交集,人工看一下,找到了一个 .ga 后缀的域名,这个域名就是最终的C2域名。
PS:流量里 bypass 过滤的方法是把 LD_PRELOAD 放到表单里上传。
题目修改
出题人本意是想让选手先分析处漏洞bypass的利用方式,再通过exp找攻击过流量,最后找C2域名。显然我的方法属于把答案偷了出来。一波讨论出题人对题目进行了一些修改:
- 提交内容改成了可能受感染的IP。
- xgoahead代码进行了调整,把 count++ 那块的修改移除了(太刻意了),增大选手分析难度。
- 之前我把所有上传elf的ip都去 passivedns 查了个遍,有dns记录的ip就是攻击ip,出题人这次把流量中的攻击ip增加了两个,同时 dns 中还没有相应请求记录。不过可以按照我原来的方法找到那两个ip,回过头分析流量中exp特征,再筛选这样就可以找出全部的四个ip了,所以出题人最后应该是在passivedns中删除了这四个ip的请求记录。
- 对流量中上传的 elf 做了些文章,选手需要去分析恶意elf的行为,从而通过 passivedns 找出剩余的受感染 IP。
所以题目正解过程如下:
- 分析漏洞,找到 bypass WAF方式。
- 通过exp,提取攻击流量,获得四个IP。
- 分析ELF行为,去 passivedns 里找出剩下的 IP。
后面分析 ELF 部分我没有做了,详细可见阿里云安全的 writeup:https://zhuanlan.zhihu.com/p/186254809?utm_source=wechat_session&utm_medium=social&utm_oi=771453567763492864&utm_content=sec&wechatShare=2&s_r=0
不过题目还是有一些投机取巧的办法的,可以把所有上传elf的流量都拖下来,就60多个ip传了elf,然后可以人工分析一波,应该就两种流量,这样就可以在无法 bypass WAF的情况下找到攻击流量。这种方法最后也没有堵死,留一种trick的做题方法23333。
总结
本次赛题评估还是学到了不少东西的。
- 勉强算是入了门逆向orz
- sample3 这个逆推思路比较新颖,CTF的密码学题目也没接触过这类
- 大数据流量的分析,靠手工和 python 脚本分析不够方便,入库操作还是比较舒服
- 学习了 xgoahead bypass WAF的姿势,其实分析那个漏洞需要动态调 C,自己也不太熟
- …
看到今年 Datacon 圆满结束,希望大家也能在这次 Datacon 中有所收获!
